
Did you know that organisations are predicted to reach between 221 and 552 zettabytes of data by the end of 2026?
This explosion of information presents incredible opportunities, but also significant challenges, particularly when it comes to extracting that data efficiently. Slow and complex data extraction processes can cripple productivity, delay critical decision-making, and ultimately hinder business growth.
If your team is wrestling with sluggish data pipelines or tangled extraction logic, you’re not alone. Fortunately, there are proven strategies to streamline this vital process and unlock the true potential of your data.
This blog breaks down the real reasons data extraction becomes slow and complex, explains how to diagnose the underlying causes, and outlines practical ways to fix them using modern data platforms and proven extraction approaches, before performance issues start holding your organisation back.
What is Data Extraction?
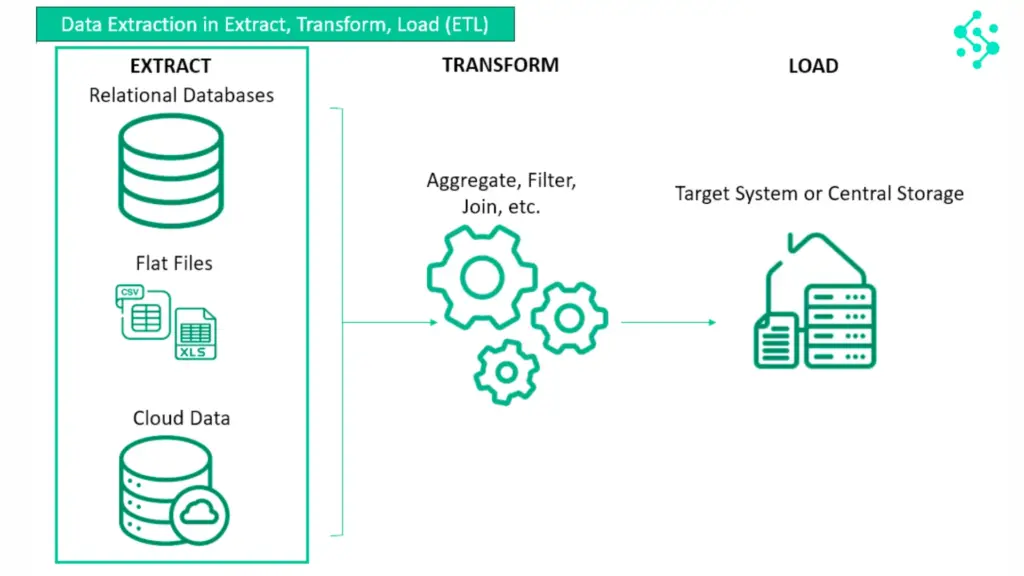
Data extraction is the process of pulling data from different systems so it can be used for reporting, analysis, or decision-making.
In simple terms, it’s how you get data out of tools and into a format you can actually use.
For most teams, this involves exporting data, cleaning it, and combining it into one view. Even today, much of this is still done manually.
Common Root Causes of Slow Data Extraction
- Schema complexity: Overly normalised source schemas requiring excessive joins; mismatched data types forcing type conversions
- Transformation logic: Heavy in-flight transformations during extraction rather than post-load; row-by-row processing instead of set-based operations
- Incremental load failures: Full refreshes running when incremental should work; missing or incorrect change data capture (CDC) logic
- Connector limits: API rate limits, pagination issues, or connector overhead in legacy ETL tools
- Network and latency: On-premises to cloud transfer bottlenecks; large payload sizes without compression
How to Diagnose Data Extraction Performance Issues?
- Review extraction logs: Identify which stages consume the most time (connection, query execution, data transfer, transformation)
- Profile source queries: Use execution plans to spot slow joins, missing indexes, or table scans
- Check incremental logic: Validate watermark columns and CDC mechanisms are working correctly
- Monitor connector behaviour: Track API call volumes, rate limit hits, and retry patterns
- Measure payload size: Assess whether compression or selective column extraction could reduce transfer time
Modern Approaches to Solving Data Extraction Challenges
The right technology stack is paramount. Cloud-based data platforms have revolutionized data management, offering scalability, flexibility, and advanced capabilities.
- ELT over ETL: Moving transformation logic downstream to reduce extraction overhead
- Cloud-native data platforms: Microsoft Fabric, Snowflake, Databricks, how they handle extraction differently
- Change data capture (CDC): Capturing only changed data to avoid full refreshes
- Connector optimisation: Using platform-native connectors (e.g., Fabric pipelines, Azure Data Factory) vs third-party tools
- Specialised extraction tools: Where tools like Xtract fit within the broader landscape (one option among several)
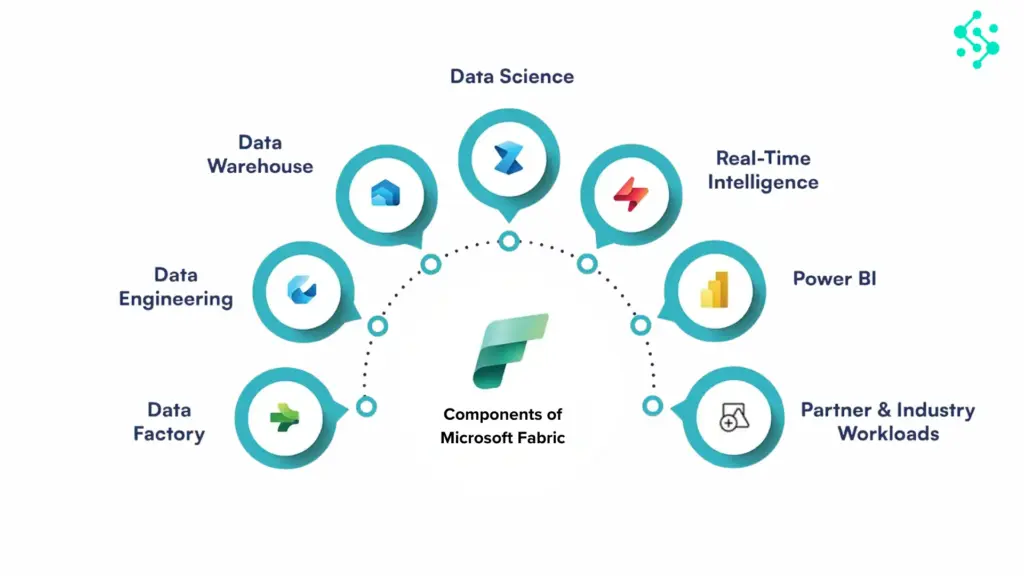
Why Platforms Like Microsoft Fabric Help?
Modern platforms like Microsoft Fabric have changed how companies manage data. They make it possible to bring data into one place, run analytics, and build for the future with AI and machine learning.
In real-world use, this can be a major step forward.
As one team described after moving to Fabric, they were able to build “a connected data environment, with the ability to do historic trend analysis and a foundation for AI and machine learning.”
That kind of shift matters.
But even with that in place, one challenge often remains, accessing data quickly for day-to-day use.
These platforms are built for scale and infrastructure. They still require setup, expertise, and ongoing management.
For many teams, that means the same bottleneck still exists.
How Xtract Simplifies Data Extraction?
For organisations managing SAP, Oracle, or legacy ERP systems, data extraction is rarely straightforward. These platforms store enormous volumes of data across deeply normalised schemas, often requiring dozens of joins to reconstruct a single business object. Change data capture mechanisms may be absent or unreliable. API limits constrain throughput. And performance bottlenecks multiply as data volumes grow, leaving engineering teams caught between building complex custom pipelines or accepting delays that slow reporting and analytics.
This is where specialised extraction tools become strategically valuable. After diagnosing root causes and evaluating modern approaches, ELT patterns, cloud-native platforms, and incremental refresh strategies, organisations often find that native connectors and general-purpose ETL tools struggle with the complexity and scale of SAP and ERP extraction. Xtract was designed specifically for this scenario.
Where Xtract Adds Value
Xtract addresses the challenges that make SAP and complex ERP extraction difficult:
- Performance at scale: Xtract extracts data directly from source systems using optimised connectors that reduce query overhead and minimise transformation during extraction. This lowers the time required to move large datasets and reduces strain on source systems, particularly important when extraction windows are tight or source performance is already constrained.
- Incremental load reliability: One of the most common causes of slow extraction is unnecessary full refreshes. Xtract supports robust incremental extraction logic, capturing only changed or new records rather than reloading entire tables. This reduces data volumes, shortens refresh cycles, and lowers infrastructure costs.
- Reduced transformation overhead: By extracting data in a clean, usable format and leaving complex transformations to downstream platforms, Xtract aligns naturally with ELT patterns. This simplifies pipelines, accelerates extraction, and allows transformation logic to leverage the compute power of modern data platforms rather than bottlenecking during the extract phase.
- Reliability and monitoring: Xtract provides visibility into extraction performance, logs failures clearly, and retries intelligently. For engineering teams managing dozens of extraction workflows, this operational reliability reduces firefighting and allows focus on higher-value work.
Xtract with Microsoft Fabric
Microsoft Fabric provides a unified data foundation, connecting storage, compute, governance, and analytics in one platform. Xtract complements this by making data from complex source systems accessible and usable within that foundation.
Fabric handles what happens next: data lands in OneLake, transformations run in Lakehouse or Data Warehouse, governance is enforced centrally, and insights are surfaced through Power BI or AI workloads.
Xtract handles how it gets there: efficiently pulling data from SAP S/4HANA, Oracle EBS, or other challenging sources without requiring custom code or brittle integration logic.
Together, they remove the friction between complex source systems and modern analytics. Fabric provides the platform; Xtract accelerates the flow of data into it.
As one client put it, success came from working with a partner that “felt like an extension of our team… with a willingness to roll up their sleeves and work through challenges.”
That combination of the right tools and the right approach is what removes friction.
The Emerging Role of AI and Machine Learning
While the focus here is on solving current extraction challenges, AI and machine learning are beginning to play a supporting role. AI-assisted tools can now help with schema mapping, data quality detection, and even generating extraction logic automatically. These capabilities reduce manual configuration effort and help teams move faster.
However, as discussed in our earlier piece on intelligent data use, technology alone is not sufficient. The true value lies in combining the right tools with a clear strategy, strong governance, and teams capable of applying them thoughtfully. Efficient extraction is the first step; what organisations do with that data determines the outcome.
When Xtract Is the Right Choice
Xtract makes most sense for organisations managing:
- SAP or Oracle ERP systems with complex schemas and large data volumes
- Incremental load requirements where native connectors fail or underperform
- Tight extraction windows that demand performance and reliability
- Migration or modernisation projects moving legacy data into Microsoft Fabric or other cloud platforms
For simpler data sources or scenarios where native connectors perform well, Xtract may not be necessary. The decision comes down to complexity, scale, and the cost of delay. Where extraction is a bottleneck and particularly where SAP or ERP systems are involved, Xtract is often the preferred option.
Struggling with slow or complex data extraction processes?
Discover how organisations are simplifying data access and reducing dependency on manual workflows.
Learn how to extract data faster from multiple sources. Contact us today for a quick demo or try it for free.

